Code
library(tidyverse)
library(tidymodels)
imdb <- read_rds("https://github.com/curso-r/livro-material/raw/master/assets/data/imdb.rds")Pacote Tidymodels
Você pode baixar os dados do IMDB aqui.
Vamos iniciar carregando os pacotes necessários:
library(tidyverse)
library(tidymodels)
imdb <- read_rds("https://github.com/curso-r/livro-material/raw/master/assets/data/imdb.rds")str(imdb)tibble [11,340 × 20] (S3: tbl_df/tbl/data.frame)
$ id_filme : chr [1:11340] "tt0092699" "tt0037931" "tt0183505" "tt0033945" ...
$ titulo : chr [1:11340] "Broadcast News" "Murder, He Says" "Me, Myself & Irene" "Never Give a Sucker an Even Break" ...
$ ano : num [1:11340] 1987 1945 2000 1941 2005 ...
$ data_lancamento : chr [1:11340] "1988-04-01" "1945-06-23" "2000-09-08" "1947-05-02" ...
$ generos : chr [1:11340] "Comedy, Drama, Romance" "Comedy, Crime, Mystery" "Comedy" "Comedy, Musical" ...
$ duracao : num [1:11340] 133 91 116 71 99 87 114 104 95 111 ...
$ pais : chr [1:11340] "USA" "USA" "USA" "USA" ...
$ idioma : chr [1:11340] "English, Spanish, French, German" "English" "English, German" "English" ...
$ orcamento : num [1:11340] 2.0e+07 NA 5.1e+07 NA NA NA 1.5e+07 3.5e+07 NA NA ...
$ receita : num [1:11340] 6.73e+07 NA 1.49e+08 NA 3.09e+05 ...
$ receita_eua : num [1:11340] 51249404 NA 90570999 NA 309404 ...
$ nota_imdb : num [1:11340] 7.2 7.1 6.6 7.2 5.9 6.1 7.1 5.5 7.1 5.7 ...
$ num_avaliacoes : num [1:11340] 26257 1639 219069 2108 2953 ...
$ direcao : chr [1:11340] "James L. Brooks" "George Marshall" "Bobby Farrelly, Peter Farrelly" "Edward F. Cline" ...
$ roteiro : chr [1:11340] "James L. Brooks" "Lou Breslow, Jack Moffitt" "Peter Farrelly, Mike Cerrone" "John T. Neville, Prescott Chaplin" ...
$ producao : chr [1:11340] "Amercent Films" "Paramount Pictures" "Twentieth Century Fox" "Universal Pictures" ...
$ elenco : chr [1:11340] "William Hurt, Albert Brooks, Holly Hunter, Robert Prosky, Lois Chiles, Joan Cusack, Peter Hackes, Christian Cle"| __truncated__ "Fred MacMurray, Helen Walker, Marjorie Main, Jean Heather, Porter Hall, Peter Whitney, Mabel Paige, Barbara Pepper" "Jim Carrey, Renée Zellweger, Anthony Anderson, Mongo Brownlee, Jerod Mixon, Chris Cooper, Michael Bowman, Richa"| __truncated__ "W.C. Fields, Gloria Jean, Leon Errol, Billy Lenhart, Kenneth Brown, Margaret Dumont, Susan Miller, Franklin Pan"| __truncated__ ...
$ descricao : chr [1:11340] "Take two rival television reporters: one handsome, one talented, both male. Add one Producer, female. Mix well,"| __truncated__ "A pollster stumbles on a family of murderous hillbillies, and joins in their search for hidden treasure." "A nice-guy cop with Dissociative Identity Disorder must protect a woman on the run from a corrupt ex-boyfriend "| __truncated__ "A filmmaker attempts to sell a surreal script he has written, which comes to life as he pitches it." ...
$ num_criticas_publico: num [1:11340] 142 35 502 35 48 26 125 45 145 52 ...
$ num_criticas_critica: num [1:11340] 62 10 161 18 15 14 72 74 55 29 ...set.seed(2024)
imdb_split <- initial_split(imdb,
prop = 0.75,
strata = nota_imdb)Escolhemos strata=nota_imdb porque queremos que nota_imdb seja nossa variável de saída, ou seja, queremos prever a nota de um determinado filme, com base em certos atributos (iremos escolher o atributos na etapa seguinte).
Agora que criamos um objeto split , podemos usá-lo para separar nossos dados em treino e teste, utilizando as funções a seguir:
treino <- training(imdb_split)
teste <- testing(imdb_split)Podemos verificar que os dados foram divididos conforme solicitado:
nrow(treino)/nrow(imdb)[1] 0.7498236nrow(teste)/nrow(imdb)[1] 0.2501764parsnipVamos construir um modelo simples de regressão linear, onde a nota_imdb depende de:
num_avaliacoes,num_criticas_publico enum_criticas_critica.lm_model <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")fit:formula <- nota_imdb ~ num_avaliacoes +
num_criticas_publico +
num_criticas_critica
lm_fit <- lm_model %>%
fit(formula,
data=treino)O modelo treinado lm_fit pode ser observado mais de perto utilizando tidy:
tidy(lm_fit)# A tibble: 4 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 5.93 0.0150 396. 0
2 num_avaliacoes 0.00000274 0.000000173 15.9 3.82e-56
3 num_criticas_publico -0.000220 0.0000635 -3.46 5.34e- 4
4 num_criticas_critica 0.00155 0.000189 8.20 2.84e-16Para avaliar a performance do modelo, usamos last_fit no objeto lm_model e calculamos os indicadores de performance utilizando collect_metrics:
lm_last <- lm_model %>%
last_fit(formula,
split = imdb_split)
lm_last %>%
collect_metrics()# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 1.05 Preprocessor1_Model1
2 rsq standard 0.0782 Preprocessor1_Model1recipesVamos aplicar algumas transformações utilizando step
Primeiro, vamos aplicar step_log para num_avaliacoes
lm_model_rec <- recipe(formula,
data=treino) %>%
step_log(num_avaliacoes, base = 10)num_criticas_publico e num_criticas_critica:lm_model_rec <- recipe(formula,
data=treino) %>%
step_log(num_avaliacoes, base = 10) %>%
step_impute_knn(all_predictors())recipelm_model_rec vamos utilizar prep()lm_model_rec_prep <- lm_model_rec %>%
prep(training = treino)e finalmente vamos produzir o novo dataset de treino com as transformações que fizemos.
vamos utilizar new_data=NULL para produzir o dataset de treino
treino_prep <- lm_model_rec_prep %>%
bake(new_data = NULL)Os dados de treino pré-processados encontram-se no dataset treino_prep
treino_prep %>% head(5)# A tibble: 5 × 4
num_avaliacoes num_criticas_publico num_criticas_critica nota_imdb
<dbl> <dbl> <dbl> <dbl>
1 3.09 56 31 4.7
2 3.22 32 46 4.8
3 3.50 28 12 5.4
4 3.84 50 26 4.4
5 3.52 111 3 3.5teste_prepstep_corrExistem muitas outras transformações com uso de step_ que podem ser de utilidade dependendo do contexto dos dados.
Quando duas variáveis estão muito correlacionadas, p.ex., o modelo de ML pode sofrer de multicolinearidade, utiliza-se:
lm_model_rec <- recipe(formula,
data=treino) %>%
step_log(num_avaliacoes, base = 10) %>%
step_impute_knn(all_predictors()) %>%
step_corr(all_numeric(), threshold = 0.85)threshold = 0.85 mas poderia ter sido escolhido outro valor, p.ex. 0.9step_normalizeTambém é possível normalizar colunas (processo similar ao utilizado no kmeans
Para isso, cada valor da coluna e subtraido pela média e dividido pelo desvio padrão.
É recomendado em todas as variáveis numéricas, utilizando step_normalize(all_numeric)
lm_model_rec <- recipe(formula,
data=treino) %>%
step_log(num_avaliacoes, base = 10) %>%
step_impute_knn(all_predictors()) %>%
step_corr(all_numeric(), threshold = 0.85) %>%
step_normalize(all_numeric(), -all_outcomes())step_dummyfactor é recomendável convertê-las a dummies.all_nominal() como argumento do step_dummylm_model_rec <- recipe(formula,
data=treino) %>%
step_log(num_avaliacoes, base = 10) %>%
step_impute_knn(all_predictors()) %>%
step_corr(all_numeric(), threshold = 0.85) %>%
step_normalize(all_numeric(), -all_outcomes()) %>%
step_dummy(all_nominal())Uma vez que todas as etapas de pré-processamento foram definidas, deve-se criar novos datasets de treino e teste.
Utiliza-se a função prep() para preparar a recipe e bake() para criar os datasets
lm_model_prep <- lm_model_rec %>%
prep(training=treino)
treino_prep <- lm_model_prep %>%
bake(new_data = NULL)
teste_prep <- lm_model_prep %>%
bake(new_data = teste)lm_fit_prep <- lm_model %>%
fit(formula,
data=treino_prep)lm_fit_prepparsnip model object
Call:
stats::lm(formula = nota_imdb ~ num_avaliacoes + num_criticas_publico +
num_criticas_critica, data = data)
Coefficients:
(Intercept) num_avaliacoes num_criticas_publico
6.10355 0.41911 0.04434
num_criticas_critica
-0.05613 predict().previsao <- predict(lm_fit_prep,
new_data = teste_prep)
resultados <- teste_prep %>%
select(nota_imdb) %>%
bind_cols(previsao)resultados %>%
rsq(nota_imdb, estimate = .pred)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.118É possível fazer um gráfico mostrando a qualidade do ajuste entre a variável de saída real e a previsão.
resultados %>%
ggplot(aes(nota_imdb, .pred))+
geom_point()+
geom_abline(color="lightblue", linetype =2)+
coord_obs_pred()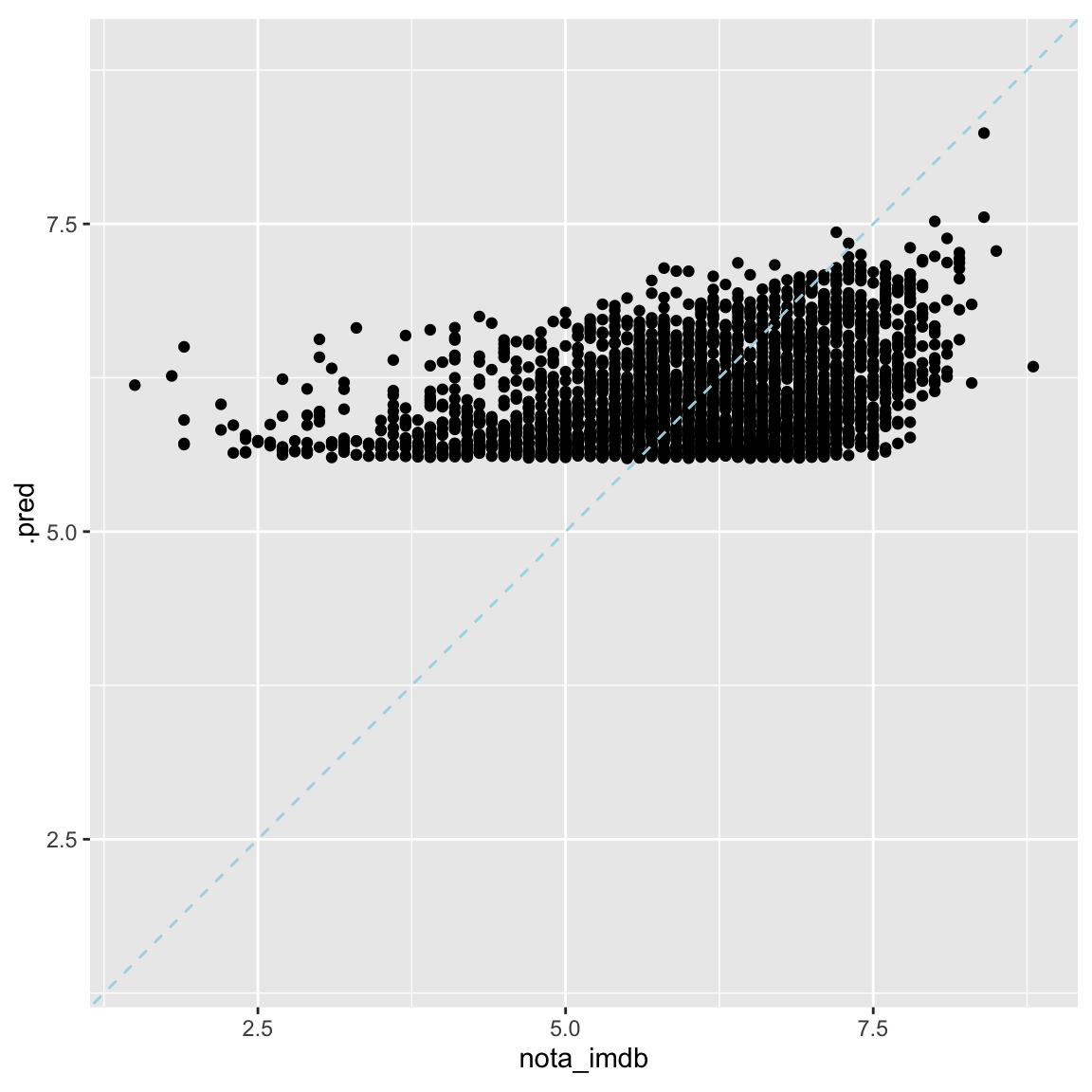
workflowsworkflow()wkfl <- workflow() %>%
add_model(lm_model) %>%
add_recipe(lm_model_rec)workflows treina-se novamente o modelo com last_fit() e avalia-se novamente o modelo com collect_metrics()workflowslm_fit_wkfl <- wkfl %>%
last_fit(split=imdb_split)
lm_fit_wkfl %>%
collect_metrics()# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 1.03 Preprocessor1_Model1
2 rsq standard 0.118 Preprocessor1_Model1vfold_cv()set.seed(9988)
folds <- vfold_cv(treino,
v=10, strata = nota_imdb)
folds# 10-fold cross-validation using stratification
# A tibble: 10 × 2
splits id
<list> <chr>
1 <split [7651/852]> Fold01
2 <split [7651/852]> Fold02
3 <split [7652/851]> Fold03
4 <split [7653/850]> Fold04
5 <split [7653/850]> Fold05
6 <split [7653/850]> Fold06
7 <split [7653/850]> Fold07
8 <split [7653/850]> Fold08
9 <split [7653/850]> Fold09
10 <split [7655/848]> Fold10Pode-se aproveitar o workflow (que inclui o modelo parsnip e a recipes ).
Mas deve-se utilizar fit_resamples ao inves de fit
lm_fit_vc <- wkfl %>%
fit_resamples(resamples = folds)
lm_fit_vc %>%
collect_metrics()# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 1.07 10 0.00488 Preprocessor1_Model1
2 rsq standard 0.127 10 0.00954 Preprocessor1_Model1summarize = FALSE dentro de collect_metrics(), então teremos um detalhamento das métricas por cada fold.lm_fit_vc %>%
collect_metrics(summarize = FALSE)# A tibble: 20 × 5
id .metric .estimator .estimate .config
<chr> <chr> <chr> <dbl> <chr>
1 Fold01 rmse standard 1.05 Preprocessor1_Model1
2 Fold01 rsq standard 0.134 Preprocessor1_Model1
3 Fold02 rmse standard 1.05 Preprocessor1_Model1
4 Fold02 rsq standard 0.136 Preprocessor1_Model1
5 Fold03 rmse standard 1.08 Preprocessor1_Model1
6 Fold03 rsq standard 0.183 Preprocessor1_Model1
7 Fold04 rmse standard 1.08 Preprocessor1_Model1
8 Fold04 rsq standard 0.104 Preprocessor1_Model1
9 Fold05 rmse standard 1.06 Preprocessor1_Model1
10 Fold05 rsq standard 0.0965 Preprocessor1_Model1
11 Fold06 rmse standard 1.06 Preprocessor1_Model1
12 Fold06 rsq standard 0.104 Preprocessor1_Model1
13 Fold07 rmse standard 1.06 Preprocessor1_Model1
14 Fold07 rsq standard 0.159 Preprocessor1_Model1
15 Fold08 rmse standard 1.09 Preprocessor1_Model1
16 Fold08 rsq standard 0.0853 Preprocessor1_Model1
17 Fold09 rmse standard 1.04 Preprocessor1_Model1
18 Fold09 rsq standard 0.133 Preprocessor1_Model1
19 Fold10 rmse standard 1.08 Preprocessor1_Model1
20 Fold10 rsq standard 0.138 Preprocessor1_Model1Uma vez identificado todo o processo de treinamento e avaliação de modelo utilizando a regressão linear, podemos utilizar a mesma lógica de parsnip, recipes e workflows em outros tipos de modelos.
Para treinar árvores de decisão utilizamos decision_tree() com set_engine("rpart") e set_mode("regression")
Para treinar random forests utilizamos rand_forest() com set_engine("ranger") e set_mode("regression")
Para treinar k-nearest neighbors utilizamos nearest_neighbor() com set_engine("knn") e set_mode("regression")
Para treinar modelos de regressão lasso utilizamos linear_reg(penalty=0.1, mixture=1) e set_engine("glmnet")
Para treinar modelos de regressão ridge utilizamos linear_reg(penalty=0.1, mixture=0) e set_engine("glmnet")
linear_reg(penalty=0.1, mixture=0.5) e set_engine("glmnet")Vamos escolher uma variável categórica para ser a nossa saída.
o primeiro ‘level’ deve ser a classe positiva
set.seed(202401)
imdb_class <- imdb %>%
mutate(Lucro = receita - orcamento,
Lucro_fac = factor(ifelse(Lucro>0, 'yes' ,'no')))
imdb_class$Lucro_fac <- relevel(imdb_class$Lucro_fac, ref = "yes")
levels(imdb_class$Lucro_fac)[1] "yes" "no" imdb_split <- initial_split(imdb_class,
prop = 0.75,
strata = Lucro_fac)
treino <- training(imdb_split)
testing <- testing(imdb_split)Fazemos um novo split, agora utilizando a variável categórica
logistic_model <- logistic_reg() %>%
set_engine("glm") %>%
set_mode("classification")
logistic_fit <- logistic_model %>%
fit(Lucro_fac ~ duracao + nota_imdb + num_avaliacoes,
data = treino)
class_preds <- logistic_fit %>%
predict(new_data = teste,
type = "class")
class_preds# A tibble: 2,837 × 1
.pred_class
<fct>
1 no
2 no
3 yes
4 no
5 no
6 no
7 no
8 no
9 no
10 no
# ℹ 2,827 more rowsPodemos criar um workflow para facilitar a construção do modelo de treinamento.
Similarmente ao caso da regressão, podemos reaproveitar vários dos step_ que aprendemos antes.
formula <- Lucro_fac ~ duracao + nota_imdb + num_avaliacoes
logistic_rec <- recipe(formula,
data=treino) %>%
step_log(num_avaliacoes, base = 10) %>%
step_impute_knn(all_predictors()) %>%
step_corr(all_numeric(), threshold = 0.85) %>%
step_normalize(all_numeric()) %>%
step_dummy(all_nominal(), -all_outcomes())wkfl <- workflow() %>%
add_model(logistic_model) %>%
add_recipe(logistic_rec)set.seed(2233)
folds <- vfold_cv(treino,
v=10, strata = Lucro_fac)metrics_custom <- metric_set(accuracy, roc_auc, sensitivity, specificity)
logistic_fit_vc <- wkfl %>%
fit_resamples(resamples = folds,
metrics = metrics_custom,
control = control_resamples(save_pred = TRUE))
logistic_fit_vc %>%
collect_metrics()# A tibble: 4 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 accuracy binary 0.738 10 0.00680 Preprocessor1_Model1
2 roc_auc binary 0.815 10 0.00505 Preprocessor1_Model1
3 sensitivity binary 0.806 10 0.00664 Preprocessor1_Model1
4 specificity binary 0.642 10 0.0151 Preprocessor1_Model1logistic_fit_vc %>%
collect_predictions()# A tibble: 8,504 × 7
.pred_class .pred_yes .pred_no id .row Lucro_fac .config
<fct> <dbl> <dbl> <chr> <int> <fct> <chr>
1 no 0.383 0.617 Fold01 21 <NA> Preprocessor1_Model1
2 no 0.0885 0.911 Fold01 27 <NA> Preprocessor1_Model1
3 no 0.0901 0.910 Fold01 35 no Preprocessor1_Model1
4 no 0.113 0.887 Fold01 48 <NA> Preprocessor1_Model1
5 no 0.120 0.880 Fold01 60 <NA> Preprocessor1_Model1
6 no 0.164 0.836 Fold01 77 <NA> Preprocessor1_Model1
7 no 0.288 0.712 Fold01 95 <NA> Preprocessor1_Model1
8 yes 0.703 0.297 Fold01 96 no Preprocessor1_Model1
9 yes 0.699 0.301 Fold01 97 no Preprocessor1_Model1
10 no 0.107 0.893 Fold01 111 <NA> Preprocessor1_Model1
# ℹ 8,494 more rowslogistic_fit_vc %>%
collect_predictions() %>%
group_by(id) %>%
roc_curve(Lucro_fac, .pred_yes) %>%
autoplot()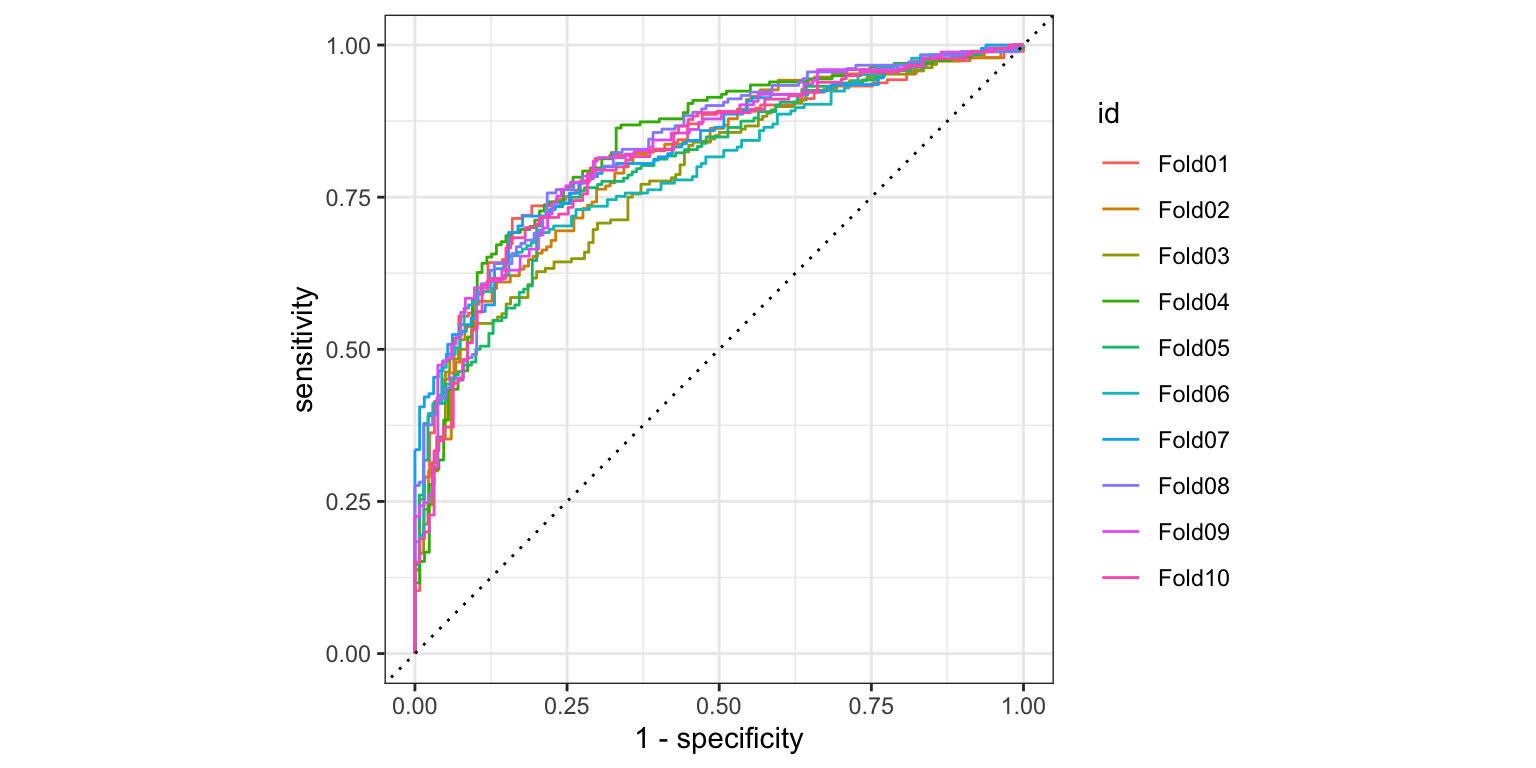
Por fim vamos rodar novamente o modelo com os dados de teste utilizando last_fit
final <- wkfl %>%
last_fit(imdb_split)
resultados <- final %>%
collect_predictions()
metrics_custom(resultados,
truth = Lucro_fac,
estimate = .pred_class, .pred_yes)# A tibble: 4 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.720
2 sensitivity binary 0.800
3 specificity binary 0.602
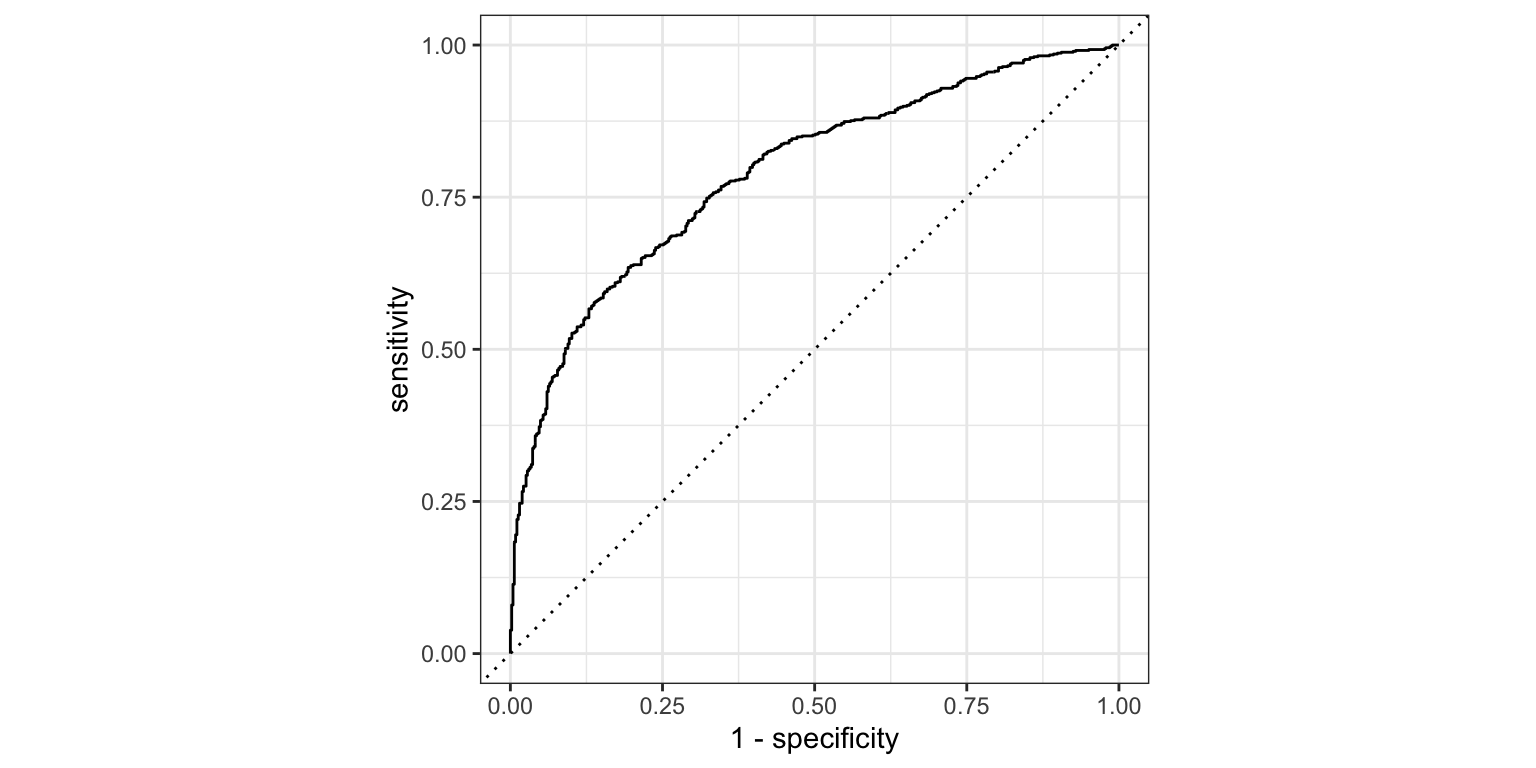
4 roc_auc binary 0.789resultados %>%
roc_curve(Lucro_fac, .pred_yes) %>%
autoplot()