library(tidyverse)
library(readxl) # para fazer leitura de arquivos excel
library(knitr) # para formatar tabelasTutorial 2 - Ggplot2 e Tidyverse
Carregando os dados
Neste tutorial vamos aprender um pouco mais sobre o ggplot em conjunto com os outros pacotes do tidyverse.
Para praticar, vamos usar o dataset netflix_series_limpo.xlsx, o dataset NetflixViewingHistory.csv e o dataset imdb_series.xlsx e o dataset imdb.rds de filmes. Portanto, o primeiro passo será carregar os datasets:
netflix <- read_xlsx("data1ggplot/netflix_series_limpo.xlsx")
imdb <- read_xlsx("data1ggplot/imdb_series.xlsx")
imdb_filmes <- read_rds("data1ggplot/imdb.rds") #está usando uma função do pacote readr do tidyverse
netflix_filmes <- read_csv("data1ggplot/NetflixViewingHistory.csv") %>%
separate(Title, c("movie_title","season","episode"),":") %>%
filter(is.na(episode)) %>%
select(movie_title, Date) %>%
mutate(Date = lubridate::as_date(Date, format="%m/%d/%y")) %>%
left_join(imdb_filmes, by=c("movie_title"="titulo")) %>%
filter(!is.na(id_filme))Rows: 1429 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): Title, Date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 3 pieces. Additional pieces discarded in 77 rows [6, 7, 8, 9, 10, 13,
17, 18, 43, 44, 78, 97, 98, 99, 104, 161, 175, 176, 216, 282, ...].Warning: Expected 3 pieces. Missing pieces filled with `NA` in 308 rows [5, 11, 12, 16,
19, 20, 31, 32, 33, 36, 37, 39, 40, 41, 42, 45, 46, 48, 49, 57, ...].Warning in left_join(., imdb_filmes, by = c(movie_title = "titulo")): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 5 of `x` matches multiple rows in `y`.
ℹ Row 88 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.Tipos de visualizações
A visualização de dados é uma ferramenta poderosa que não só simplifica a compreensão de grandes volumes de dados, mas também desempenha um papel crucial na estatística aplicada e no aprendizado de máquina. Imagine o potencial de desbloquear insights valiosos e identificar padrões ocultos em seus conjuntos de dados! Com um conhecimento prévio do assunto, você pode explorar as nuances dos dados e revelar conexões significativas que podem surpreender e iluminar tanto você quanto sua audiência.
Gráfico de Dispersão
Quando há necessidade de encontrar correlações, são utilizados os gráficos de dispersão. Se existir um conjunto de dados XY, então um gráfico de dispersão é utilizado para encontrar a relação entre as variáveis X e Y.
Exemplo Base
Para realizar gráficos de dispersão, precisamos passar a função geom_point() como uma nova camada do ggplot. As coordenadas x e y devem ser numéricas necessariamente. Vamos usar como exemplo, o dataframe imdb_filmes.
No exemplo, a posição do ponto no eixo x pode ser dada pela coluna orcamento e a posição do ponto no eixo y pela coluna receita.
imdb_filmes %>%
ggplot()
Adicionando cores
Podemos adicionar cores grupalmente para todos os pontos ou podemos usar alguma outra variável para criar cores em gradiente
Para ver mais detalhamento da função geom_point() recomenda-se a leitura do Capítulo 8 do Livro “Curso-R”.
Gráfico de Barras
Um gráfico de barras também exibe tendências ao longo do tempo. No caso de múltiplas variáveis, um gráfico de barras pode facilitar a comparação dos dados para cada variável em todos os momentos no tempo. Por exemplo, um gráfico de barras pode ser utilizado para comparar o crescimento da empresa ano a ano.
Exemplo Base
Para realizar gráficos de barras usamos geom_col(). Vamos usar o dataframe imdb_filmes para exemplificar, ordenando as linhas por ordem decrescente de UserRating. Primeiro vamos gerar o gráfico com as configuração padrão.
imdb_filmes %>%
arrange(desc(nota_imdb)) %>%
head(10) # adicionar código do ggplot# A tibble: 10 × 20
id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
1 tt102189… As I … 2019 2019-12-06 Drama,… 62 USA Engli… 10000
2 tt6735740 Love … 2019 2019-06-23 Comedy 100 USA Engli… 3000000
3 tt0111161 The S… 1994 1995-02-10 Drama 142 USA Engli… 25000000
4 tt0068646 The G… 1972 1972-09-21 Crime,… 175 USA Engli… 6000000
5 tt5980638 The T… 2018 2020-06-19 Music,… 96 USA Engli… 90000
6 tt0071562 The G… 1974 1975-09-25 Crime,… 202 USA Engli… 13000000
7 tt0050083 12 An… 1957 1957-09-04 Crime,… 96 USA Engli… 350000
8 tt0110912 Pulp … 1994 1994-10-28 Crime,… 154 USA Engli… 8000000
9 tt0108052 Schin… 1993 1994-03-11 Biogra… 195 USA Engli… 22000000
10 tt0419781 Grave… 2005 2005-04-22 Thrill… 90 USA Engli… 1930000
# ℹ 11 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
# num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
# elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
# num_criticas_critica <dbl>Mudando os eixos e adicionando cores
Podemos mudar os eixos (trocar de eixo) usando a função coord_flip()
imdb_filmes %>%
arrange(desc(nota_imdb)) %>%
head(10)# A tibble: 10 × 20
id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
1 tt102189… As I … 2019 2019-12-06 Drama,… 62 USA Engli… 10000
2 tt6735740 Love … 2019 2019-06-23 Comedy 100 USA Engli… 3000000
3 tt0111161 The S… 1994 1995-02-10 Drama 142 USA Engli… 25000000
4 tt0068646 The G… 1972 1972-09-21 Crime,… 175 USA Engli… 6000000
5 tt5980638 The T… 2018 2020-06-19 Music,… 96 USA Engli… 90000
6 tt0071562 The G… 1974 1975-09-25 Crime,… 202 USA Engli… 13000000
7 tt0050083 12 An… 1957 1957-09-04 Crime,… 96 USA Engli… 350000
8 tt0110912 Pulp … 1994 1994-10-28 Crime,… 154 USA Engli… 8000000
9 tt0108052 Schin… 1993 1994-03-11 Biogra… 195 USA Engli… 22000000
10 tt0419781 Grave… 2005 2005-04-22 Thrill… 90 USA Engli… 1930000
# ℹ 11 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
# num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
# elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
# num_criticas_critica <dbl>Vamos aplicar tudo o aprendido num segundo exemplo, usando o dataframe imdb para mostrar os seriados com maior número de votos UserVotes.
imdb %>%
group_by(series_name) %>%
summarize(Votos = sum(UserVotes)) %>%
arrange(desc(Votos)) #adicionar ggplot# A tibble: 27 × 2
series_name Votos
<chr> <dbl>
1 The Walking Dead 2394586
2 Arquivo X 969628
3 Friends 853287
4 Sobrenatural 499046
5 Era Uma Vez 397332
6 Stranger Things 391288
7 Sherlock 373114
8 Lúcifer 298412
9 Dark 264631
10 Como Defender um Assassino 228352
# ℹ 17 more rowsVocê pode ver mais exemplos no Capítulo 8 do livro Curso-R
Gráfico de linha
Gráficos de linhas são utilizados para exibir tendências ao longo do tempo. O eixo X é geralmente utilizado para representar um período, enquanto o eixo Y é utilizado para representar a quantidade associada ao período de tempo no eixo X. Por exemplo, um gráfico de linhas pode ilustrar o horário de pico de visitas em um shopping durante o dia, dividido por dias da semana e horas.
Exemplo Base
Vamos fazer um gráfico de linha usando a função geom_line() como camada do ggplot usando o dataset netflix_filmes para mostrar o total de capítulos assistidos por dia.
netflix_filmes %>% #colocar código ggplot
group_by(Date) %>%
summarize(filmes=n())# A tibble: 114 × 2
Date filmes
<date> <int>
1 2015-08-24 2
2 2015-10-12 1
3 2015-11-16 1
4 2015-12-23 1
5 2016-01-17 2
6 2016-01-31 1
7 2016-12-29 1
8 2017-01-29 1
9 2017-03-05 2
10 2017-03-12 1
# ℹ 104 more rowsPodemos agrupar contagens usando a função floor_date do pacote lubridate para meses, trimestres, etc. Adicionalmente, podemos incluir cores.
netflix_filmes %>%
count(mes = lubridate::floor_date(Date, "month"))# A tibble: 48 × 2
mes n
<date> <int>
1 2015-08-01 2
2 2015-10-01 1
3 2015-11-01 1
4 2015-12-01 1
5 2016-01-01 3
6 2016-12-01 1
7 2017-01-01 1
8 2017-03-01 3
9 2017-05-01 1
10 2017-06-01 8
# ℹ 38 more rowsAdicionando mais de uma linha
Vamos usar o dataset imdb_filmes para comparar o desempenho dos filmes (nota imdb) em função de ter lucro ou não. Vamos adicionar também uma camada extra para nos mostrar a tendência de ambas curvas, usando geom_smooth().
imdb_filmes %>%
mutate(lucro = receita - orcamento,
lucro_factor = ifelse(lucro > 0, "Sim","Não")) %>%
filter(!is.na(lucro)) %>%
group_by(lucro_factor,ano) %>%
summarise(nota_media=mean(nota_imdb,na.rm=TRUE))`summarise()` has grouped output by 'lucro_factor'. You can override using the
`.groups` argument.# A tibble: 169 × 3
# Groups: lucro_factor [2]
lucro_factor ano nota_media
<chr> <dbl> <dbl>
1 Não 1921 8.3
2 Não 1923 7
3 Não 1925 8.2
4 Não 1927 7.8
5 Não 1928 8.1
6 Não 1931 7.85
7 Não 1932 7.9
8 Não 1933 7.65
9 Não 1934 7.55
10 Não 1935 7.3
# ℹ 159 more rowsVocê pode ver mais exemplos do geom_line() no livro Curso-R
Gráfico de Boxplot
Um gráfico de boxplot, também conhecido como diagrama de caixa, é uma ferramenta de visualização estatística que fornece uma representação compacta e informativa da distribuição de um conjunto de dados. Consiste em um retângulo (“caixa”) que se estende de um quartil ao outro, com uma linha vertical (ou “whisker”) estendendo-se de cada extremidade da caixa para representar a amplitude dos dados fora do intervalo interquartil.
Exemplo Base
Vamos usar os dados do dataset imdb para comparar as notas de UserRating em cada temporada do seriado The Walking Dead.
seriado_escolhido <- "The Walking Dead"
imdb %>%
filter(series_name == seriado_escolhido) %>%
select(1,2,4,7) # A tibble: 288 × 4
series_name Episode season UserRating
<chr> <chr> <dbl> <dbl>
1 The Walking Dead Seed 3 8.9
2 The Walking Dead Sick 3 8.6
3 The Walking Dead Walk with Me 3 8.2
4 The Walking Dead Killer Within 3 9.3
5 The Walking Dead Say the Word 3 8.2
6 The Walking Dead Hounded 3 8.3
7 The Walking Dead When the Dead Come Knocking 3 8.6
8 The Walking Dead Made to Suffer 3 9
9 The Walking Dead The Suicide King 3 8.2
10 The Walking Dead Home 3 8.7
# ℹ 278 more rowsAdicionando cores por meio de paletas pré-definidas
Vamos adicionar cores para cada temporada, para isto precisamos incluir o argumento fill dentro da camada de estetica aes. Podemos também escolher as cores de paletas pré-definidas como: scale_fill_viridis_d() e scale_fill_brewer()
imdb %>%
filter(series_name == seriado_escolhido) %>%
select(1,2,4,7) # A tibble: 288 × 4
series_name Episode season UserRating
<chr> <chr> <dbl> <dbl>
1 The Walking Dead Seed 3 8.9
2 The Walking Dead Sick 3 8.6
3 The Walking Dead Walk with Me 3 8.2
4 The Walking Dead Killer Within 3 9.3
5 The Walking Dead Say the Word 3 8.2
6 The Walking Dead Hounded 3 8.3
7 The Walking Dead When the Dead Come Knocking 3 8.6
8 The Walking Dead Made to Suffer 3 9
9 The Walking Dead The Suicide King 3 8.2
10 The Walking Dead Home 3 8.7
# ℹ 278 more rowsGráfico de Histograma
Um histograma representa dados usando barras de alturas diferentes. Geralmente, cada barra agrupa números em intervalos em um histograma. Quanto mais alta as barras, mais dados se encaixam nesse intervalo. É usado para exibir a forma e a dispersão de amostras de um conjunto de dados contínuos. Por exemplo, podemos usar um histograma para medir as frequências de cada resposta em uma pergunta de pesquisa. As barras representariam as respostas: “ruim”, “bom” e “ótimo”.
O Histograma serve para observar a distribuição dos dados e eventualmente serve para comparar mais de uma distribuição.
Exemplo Base
Vamos continuar com os dados sobre UserRating usados anteriormente para graficar Boxplots. Neste caso, vamos graficar a distribuição do UserRating considerando apenas a contagem. Podemos usar o argumento bins ou binwidth para ajustar melhor o resultado.
imdb %>%
filter(series_name == seriado_escolhido) %>%
select(1,2,4,7) # A tibble: 288 × 4
series_name Episode season UserRating
<chr> <chr> <dbl> <dbl>
1 The Walking Dead Seed 3 8.9
2 The Walking Dead Sick 3 8.6
3 The Walking Dead Walk with Me 3 8.2
4 The Walking Dead Killer Within 3 9.3
5 The Walking Dead Say the Word 3 8.2
6 The Walking Dead Hounded 3 8.3
7 The Walking Dead When the Dead Come Knocking 3 8.6
8 The Walking Dead Made to Suffer 3 9
9 The Walking Dead The Suicide King 3 8.2
10 The Walking Dead Home 3 8.7
# ℹ 278 more rowsAgora, vamos usar o dataset imdb_filmes para verificar quão lucrativo é um determinado genero.
genero_escolhido <- "Comedy"
imdb_filmes %>%
#filter(str_detect(string = generos, pattern = genero_escolhido)) %>%
filter(generos == genero_escolhido) %>%
mutate(lucro = receita - orcamento)# A tibble: 560 × 21
id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
1 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
2 tt1242423 Dear … 2009 2011-07-01 Comedy 87 USA Engli… NA
3 tt0120434 Vegas… 1997 1997-02-14 Comedy 93 USA Engli… 25000000
4 tt5617916 Airpl… 2019 2019-08-02 Comedy 80 USA Engli… NA
5 tt7054636 A Mad… 2019 2019-03-01 Comedy 109 USA Engli… 20000000
6 tt0460925 The S… 2006 2006-01-01 Comedy 86 USA Engli… NA
7 tt0071514 For P… 1974 1974-09-13 Comedy 90 USA Engli… NA
8 tt0064683 Mondo… 1969 1969-03-14 Comedy 95 USA Engli… 2100
9 tt1073498 Meet … 2008 2008-04-24 Comedy 87 USA Engli… 30000000
10 tt0489085 I-See… 2006 2006-03-08 Comedy 92 USA Engli… 6200000
# ℹ 550 more rows
# ℹ 12 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
# num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
# elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
# num_criticas_critica <dbl>, lucro <dbl>Adicionando cores
Podemos melhorar a apresentação, escolhendo cores diferentes adicionando o argumento fill dentro de geom_histogram().
imdb_filmes %>%
#filter(str_detect(string = generos, pattern = genero_escolhido)) %>%
filter(generos == genero_escolhido) %>%
mutate(lucro = receita - orcamento) # A tibble: 560 × 21
id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
1 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
2 tt1242423 Dear … 2009 2011-07-01 Comedy 87 USA Engli… NA
3 tt0120434 Vegas… 1997 1997-02-14 Comedy 93 USA Engli… 25000000
4 tt5617916 Airpl… 2019 2019-08-02 Comedy 80 USA Engli… NA
5 tt7054636 A Mad… 2019 2019-03-01 Comedy 109 USA Engli… 20000000
6 tt0460925 The S… 2006 2006-01-01 Comedy 86 USA Engli… NA
7 tt0071514 For P… 1974 1974-09-13 Comedy 90 USA Engli… NA
8 tt0064683 Mondo… 1969 1969-03-14 Comedy 95 USA Engli… 2100
9 tt1073498 Meet … 2008 2008-04-24 Comedy 87 USA Engli… 30000000
10 tt0489085 I-See… 2006 2006-03-08 Comedy 92 USA Engli… 6200000
# ℹ 550 more rows
# ℹ 12 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
# num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
# elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
# num_criticas_critica <dbl>, lucro <dbl>Você pode ver mais exemplos do Histogramas e Boxplots no Cap. 8 do livro Curso-R
Podemos usar alternativamente um outro tipo de visualização muito similar, que é a geom_density(). Vamos usar os mesmos exemplos anteriores.
imdb %>%
filter(series_name == seriado_escolhido) %>%
select(1,2,4,7)# A tibble: 288 × 4
series_name Episode season UserRating
<chr> <chr> <dbl> <dbl>
1 The Walking Dead Seed 3 8.9
2 The Walking Dead Sick 3 8.6
3 The Walking Dead Walk with Me 3 8.2
4 The Walking Dead Killer Within 3 9.3
5 The Walking Dead Say the Word 3 8.2
6 The Walking Dead Hounded 3 8.3
7 The Walking Dead When the Dead Come Knocking 3 8.6
8 The Walking Dead Made to Suffer 3 9
9 The Walking Dead The Suicide King 3 8.2
10 The Walking Dead Home 3 8.7
# ℹ 278 more rowsPodemos também customizar a cor da linha e da área abaixo da densidade usando os argumentos fill e color dentro do geom_density() bem como a transparência usando alpha.
imdb_filmes %>%
#filter(str_detect(string = generos, pattern = genero_escolhido)) %>%
filter(generos == genero_escolhido) %>%
mutate(lucro = receita - orcamento)# A tibble: 560 × 21
id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
1 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
2 tt1242423 Dear … 2009 2011-07-01 Comedy 87 USA Engli… NA
3 tt0120434 Vegas… 1997 1997-02-14 Comedy 93 USA Engli… 25000000
4 tt5617916 Airpl… 2019 2019-08-02 Comedy 80 USA Engli… NA
5 tt7054636 A Mad… 2019 2019-03-01 Comedy 109 USA Engli… 20000000
6 tt0460925 The S… 2006 2006-01-01 Comedy 86 USA Engli… NA
7 tt0071514 For P… 1974 1974-09-13 Comedy 90 USA Engli… NA
8 tt0064683 Mondo… 1969 1969-03-14 Comedy 95 USA Engli… 2100
9 tt1073498 Meet … 2008 2008-04-24 Comedy 87 USA Engli… 30000000
10 tt0489085 I-See… 2006 2006-03-08 Comedy 92 USA Engli… 6200000
# ℹ 550 more rows
# ℹ 12 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
# num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
# elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
# num_criticas_critica <dbl>, lucro <dbl>E por fim, podemos comparar duas ou mais categorias. Vamos fazer isso, comparando os generos “Comedy” e “Drama” para saber se há diferenças significativas em termos de lucro. Para isto, vamos incluir o argumento group dentro da camada aes além de fill e color. Adicionalmente podemos incluir alpha dentro de geom_density().
imdb_filmes %>%
#filter(str_detect(string = generos, pattern = genero_escolhido)) %>%
filter(generos %in% c("Comedy","Drama")) %>%
mutate(lucro = receita - orcamento)# A tibble: 1,188 × 21
id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
1 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
2 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
3 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
4 tt1242423 Dear … 2009 2011-07-01 Comedy 87 USA Engli… NA
5 tt0109514 Curse… 1994 1995-05-05 Drama 102 USA Engli… 12577385
6 tt0120434 Vegas… 1997 1997-02-14 Comedy 93 USA Engli… 25000000
7 tt0068528 The E… 1972 1973-05-30 Drama 100 USA Engli… NA
8 tt5617916 Airpl… 2019 2019-08-02 Comedy 80 USA Engli… NA
9 tt0049800 Storm… 1956 1956-07-31 Drama 85 USA Engli… NA
10 tt7054636 A Mad… 2019 2019-03-01 Comedy 109 USA Engli… 20000000
# ℹ 1,178 more rows
# ℹ 12 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
# num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
# elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
# num_criticas_critica <dbl>, lucro <dbl>Diagramas Sankey
Diagramas Sankey são representações visuais que mostram o fluxo de dados, energia, recursos ou informações através de caminhos ou processos. Eles consistem em setas de larguras variáveis, onde a largura das setas é proporcional à quantidade de fluxo, facilitando a compreensão e análise de sistemas complexos de fluxo.
Outras customizações
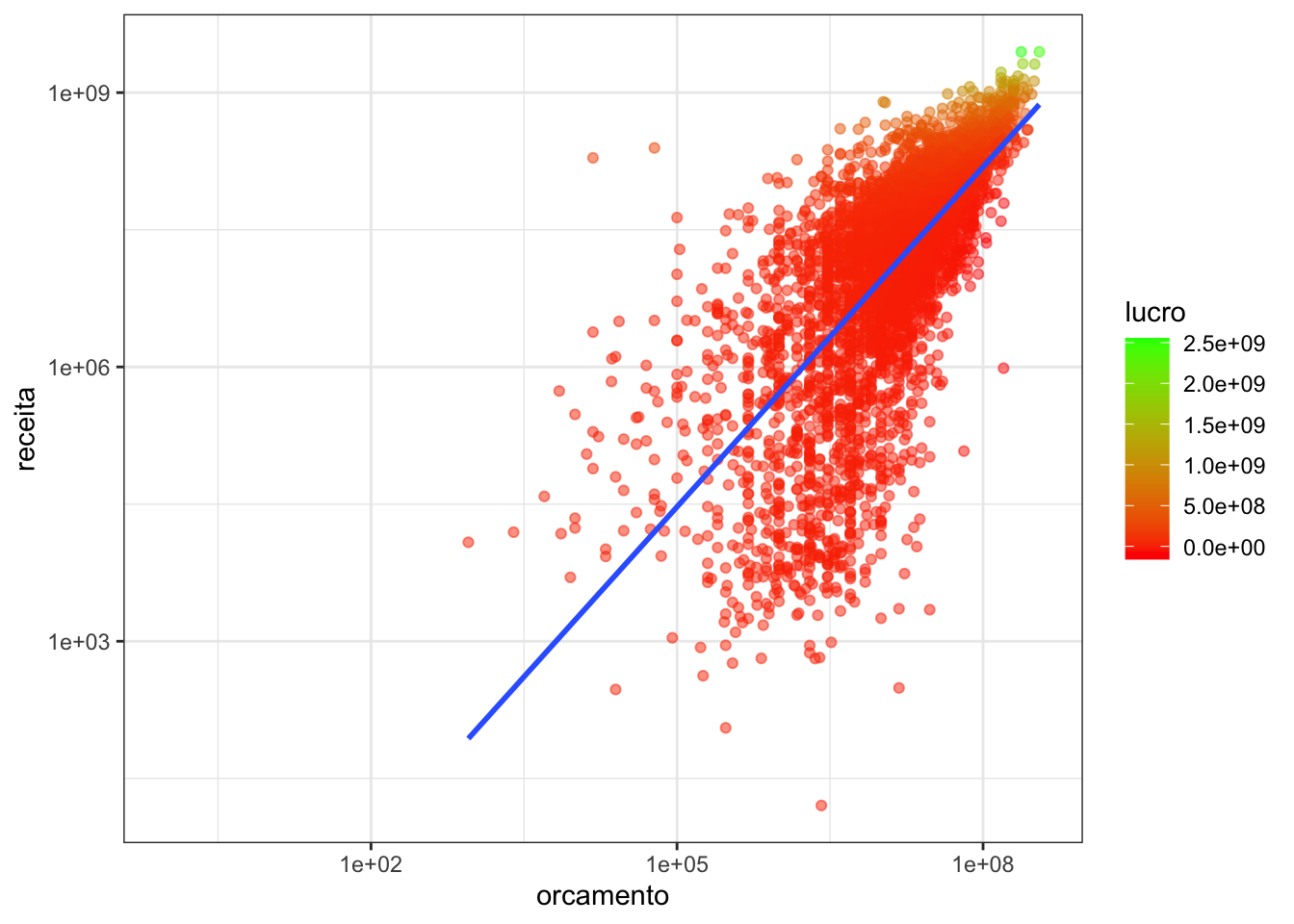
O ggplot inclui praticamente customizações infinitas, desde as mais simples, como atribuir títulos aos eixos até mudar as escalas, por exemplo usando transformações logarítmicas.
imdb_filmes %>%
mutate(lucro = receita-orcamento) %>%
ggplot(aes(x = orcamento, y = receita, color=lucro)) +
geom_point(alpha=0.5)+
scale_y_log10()+
scale_x_log10()+
geom_smooth(method = "lm", se=FALSE)+
theme_bw()+
scale_color_gradient(low = "red", high = "green")Warning in scale_x_log10(): log-10 transformation introduced infinite values.
log-10 transformation introduced infinite values.`geom_smooth()` using formula = 'y ~ x'Warning: Removed 7004 rows containing non-finite outside the scale range
(`stat_smooth()`).Warning: The following aesthetics were dropped during statistical transformation:
colour.
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?Warning: Removed 7004 rows containing missing values or values outside the scale range
(`geom_point()`).